Ordenador que predice el futuro
Previsión de la conducta humana con supercomputación a partir de noticias internacionales
Un artículo publicado el 7 de septiembre en la revista First Monday combina la supercomputación avanzada con un cuarto de siglo de noticias de todo el mundo para predecir y visualizar el comportamiento humano, desde los disturbios civiles al movimiento de los individuos.
El documento, titulado "Culturomics 2.0: Forecasting Large-Scale Human Behavior Using Global News Media Tone in Time and Space" (Culturomics 2.0: Predicción del comportamiento humano a gran escala utilizando el tono de los medios de comunicación de noticias internacionales en tiempo y espacio), utiliza el tono y la ubicación de la cobertura de noticias de todo el mundo para predecir la estabilidad de un país (incluyendo, la predicción, con carácter retroactivo, de la reciente Primavera Árabe) , estimar la ubicación final de Osama Bin Laden en un radio de 200 kilómetros alrededor de Abbottabad y descubrir las seis civilizaciones del mundo de los medios de comunicación de noticias internacionales. La investigación también demuestra que las noticias son, de hecho, cada vez más negativas, e incluso visualiza el conflicto mundial de la sociedad humana y la cooperación en el último cuarto de siglo.
Mediante el uso de la gran supercomputadora de memoria compartida Nautilus, Kalev Leetaru, de la Universidad de Illinois, en Urbana-Champaign, combinó tres archivos de noticias masivos con un total de más de 100 millones de artículos de todo el mundo, para explorar la conciencia global de los medios de comunicación.
Se utilizaron métodos avanzados de análisis tonal, geográfico y de red para producir una red de 2,4 petabytes de tamaño con más de 10 millones de personas, lugares, cosas y actividades conectadas por más de 100 billones de relaciones, captando una sección transversal de la Tierra desde los medios de comunicación . Un subconjunto de los resultados de este análisis fue reproducido, a continuación, para este estudio utilizando métodos más tradicionales y flujos de trabajo a menor escala que ofrecen un modelo para una nueva clase de investigación digital en humanidades que explora cómo se ve el mundo a sí mismo.
avances-tecnologicos.euroresidentes.com
martes, 13 de diciembre de 2011
Noticia 5 diceimbre
Nuevo método para detectar cáncer
Un espray fluorescente podría ayudar a los cirujanos a identificar rápidamente el cáncer
Los cirujanos que operan el cáncer se esfuerzan por eliminar las células cancerosas y preservar tanto tejido sano como pueden. Desafortunadamente, las células del cáncer son notoriamente difíciles de identificar a simple vista.
Un grupo dirigido por Hisataka Kobayashi, del Instituto Nacional del Cáncer, ha desarrollado un espray fluorescente que puede resaltar las células cancerosas en menos de un minuto. La idea es que los cirujanos podrían aplicarlo durante o después de una intervención para encontrar cualquier célula cancerosa que se les haya escapado.
Varios equipos de investigación han estado trabajando en marcadores fluorescentes para células cancerosas que puedan servir como guía visual para los cirujanos, pero por lo general, los otros métodos tardan mucho más en funcionar.
Los investigadores demostraron la habilidad del espray para resaltar las células cancerosas en ratones en un estudio publicado la semana pasada en la revista Science Translational Medicine. La fluorescencia es activada por una enzima denominada gamma glutamil transpeptidasa, que abunda en las células tumorales, pero no en las normales. La sonda que Kobayashi y su equipo diseñaron contiene un objetivo químico de la enzima del tumor. La enzima divide el químico al entrar en contacto con él y esto activa la señal de fluorescencia
http://avances-tecnologicos.euroresidentes.com/
Un espray fluorescente podría ayudar a los cirujanos a identificar rápidamente el cáncer
Los cirujanos que operan el cáncer se esfuerzan por eliminar las células cancerosas y preservar tanto tejido sano como pueden. Desafortunadamente, las células del cáncer son notoriamente difíciles de identificar a simple vista.
Un grupo dirigido por Hisataka Kobayashi, del Instituto Nacional del Cáncer, ha desarrollado un espray fluorescente que puede resaltar las células cancerosas en menos de un minuto. La idea es que los cirujanos podrían aplicarlo durante o después de una intervención para encontrar cualquier célula cancerosa que se les haya escapado.
Varios equipos de investigación han estado trabajando en marcadores fluorescentes para células cancerosas que puedan servir como guía visual para los cirujanos, pero por lo general, los otros métodos tardan mucho más en funcionar.
Los investigadores demostraron la habilidad del espray para resaltar las células cancerosas en ratones en un estudio publicado la semana pasada en la revista Science Translational Medicine. La fluorescencia es activada por una enzima denominada gamma glutamil transpeptidasa, que abunda en las células tumorales, pero no en las normales. La sonda que Kobayashi y su equipo diseñaron contiene un objetivo químico de la enzima del tumor. La enzima divide el químico al entrar en contacto con él y esto activa la señal de fluorescencia
http://avances-tecnologicos.euroresidentes.com/
lunes, 28 de noviembre de 2011
Smartphone que detecta anomalías en el ritmo cardiaco
Smartphone que detecta anomalías en el ritmo cardiaco
Un teléfono inteligente detecta peligro en un latido de corazón
Una nueva invención médica que aprovecha el poder de la tecnología de los teléfonos inteligentes podría revolucionar el tratamiento de los pacientes de corazón, según unos investigadores de Suiza.
La herramienta autónoma --desarrollada conjuntamente por los laboratorios de Sistemas embebidos y Circuitos de telecomunicaciones de la Ecole Polytechnique Federale de Lausanne (EPFL)-- no sólo identifica automáticamente anomalías en el ritmo cardíaco, sino que también alerta a los médicos en cuestión de segundos, ayudándoles a tratar a los pacientes con mayor rapidez.
El monitor, pequeño y ligero, consta de cuatro sensores de electrodos no invasivos pegados a la piel y conectados a un módulo de radio y un chip de ordenador que se engancha al cinturón del paciente.
Los datos se envían al teléfono inteligente del usuario, donde se pueden ver en tiempo real hasta 150 horas con una sola carga.
Unos algoritmos complejos identifican cualquier anomalía y los datos se envían a un médico para su examen a través de una imagen adjunta a un mensaje de texto o correo electrónico.
"El sistema recoge datos muy fiables y precisos", afirma uno de los investigadores, "pero sobre todo ofrece un análisis automático y una transmisión inmediata de datos al médico, evitando que éste tenga que revisar horas de datos registrados".
Los investigadores confían también en que se encontrarán otros usos para la herramienta relacionados con la salud, como el seguimiento del rendimiento deportivo o la evaluación de la dieta y la actividad física en pacientes obesos.
lunes, 21 de noviembre de 2011
Noticia del dia 21 Noviembre 2011
Los usuarios de Office para Mac pueden utilizar de esta semana Lync como nueva plataforma de comunicaciones integradas. La solución de Microsoft incorpora las herramientas más importantes que necesitan las empresas.
Además, Lync para Mac 2011 ofrece funcionalidad integrada para presencia, Mensajería instantánea, Conferencias y voz. Está diseñado para Lync Sever 2010 y Lync Online. Según Microsoft, permite controlar los costes de comunicación y mejorar la productividad de los usuarios y la eficiencia operativa.
Lync para Mac 2’11 está disponible para sus usuarios desde: SKU de Office para Mac 2011 Volume Licensing, Office para Mac Standard 2011, distintos Programas de Licenciamiento de Microsoft e incluso se puede comprar la aplicación como un volumen de licencia SKU por separado.
Los clientes que adquieran Office para Mac Standard 2011 desde el 1 de octubre de 2011 en adelante, ya tendrán su suite de oficina que incluye Lync, en lugar de Communicator para Mac.
Los clientes de Office para Mac 2011 con cobertura Software Assurance a partir de octubre de 2011, pueden utilizar Communicator 2011 para Mac o bien optar por actualizar a Lync para Mac 2011.
http://www.noticiastecnologicas.com/
ANALIZADOR LEXICO Y FASES DE UN COMPILADOR
ANALIZADOR LEXICO
Un analizador léxico o analizador lexicográfico (en inglés scanner) es un programa que recibe como entrada el código fuente de otro programa (secuencia de caracteres) y produce una salida compuesta de tokens (componentes léxicos) o símbolos. Estos tokens sirven para una posterior etapa del proceso de traducción, siendo la entrada para el analizador sintáctico (en inglés parser).
Funciones del analizador léxico.
Analizador léxico (scanner): lee la secuencia de caracteres del programa fuente, carácter a carácter, y los agrupa para formar unidades con significado propio, los componentes léxicos (toquen en ingles). Estos componentes léxicos representan:
· palabras reservadas: if, while, do,
· identificadores: asociados a variables, nombres de funciones,
· tipos definidos por el usuario, etiquetas,... Por ejemplo: posición, velocidad, tiempo,
· operadores: = * + - / == > < & ! = . . .
· símbolos especiales: ; ( ) [ ] f g ...
· constantes numéricas: literales que representan valores enteros, en coma flotante, etc., 982, 0xF678, -83.2E+2,...
· constantes de caracteres: literales que representan cadenas concretas de caracteres, \hola mundo",
·
El analizador léxico opera bajo petición del analizador sintáctico devolviendo un componente léxico conforme el analizador sintáctico lo va necesitando para avanzar en la gramática. Los componentes léxicos son los símbolos terminales de la gramática.
Suele implementarse como una subrutina del analizador sintáctico.
Cuando recibe la orden se obtiene el siguiente componente léxico, el analizador léxico lee los caracteres de entrada hasta identificar el siguiente componente léxico.

FUNCIONES DEL ANALIZADOR LEXICO
Otras funciones secundarias:
· Manejo del ¯chero de entrada del programa fuente: abrirlo, leer sus caracteres, cerrarlo y gestionar posibles errores de lectura.
· Eliminar comentarios, espacios en blanco, tabuladores y saltos de línea (caracteres no validos para formar un token).
· Inclusión de ¯cheros: # include ...
· La expansión de macros y funciones inline: # define ...
· Contabilizar el número de líneas y columnas para emitir mensajes de error.
· Reconocimiento y ejecución de las directivas de compilación (por ejemplo, para depurar u optimizar el código fuente).
· Ventajas de separar el análisis léxico y el análisis sintáctico:
· Facilita transportabilidad del traductor (por ejemplo, si decidimos en un momento dado cambiar las palabras reservadas begin y end de inicio y finn de bloque, por f y g, símbolo hay que cambiar este modulo.
· Se simplifica el diseño: el analizador es un objeto con el que se interactúa mediante ciertos métodos. Se localiza en un único modulo la lectura física de los caracteres, por lo que facilita tratamientos especializados de E/S.
Componentes Léxicos, Patrones, Lexemas
Patrón: es una regla que genera la secuencia de caracteres que puede representar a un determinado componente léxico (una expresión regular).
Lexema: cadena de caracteres que concuerda con un patrón que describe un componente léxico. Un componente léxico puede tener uno o infinitos lexemas. Por ejemplo: palabras reservadas tienen un único lexema. Los números y los identificadores tienen infinitos lexemas.

FASES DE UN COMPILADOR
Un compilador típicamente opera en fases, cada una lleva a cabo una tarea sobre el programa fuente. Las primeras tres fases suelen agruparse en una sola fase llamada fase de análisis y las últimas tres en una llamada fase de síntesis. La fase de análisis y el modulo de manejo de errores se describen posteriormente en este mismo capítulo. La fase de síntesis no es relevante en el contexto de un lenguaje multibase de datos, ya que este sigue un enfoque diferente que el de los lenguajes tradicionales, por esta razón solo se menciona.
Muchas herramientas de software que manipulan programas fuente realizan primero algún tipo de análisis, entre estas se encuentran los editores de estructuras, impresoras estéticas, verificadores estáticos y los interpretes.
Estructura de un Compilador.
Cualquier compilador debe realizar dos tareas principales: análisis del programa a compilar y síntesis de un programa en lenguaje maquina que, cuando se ejecute, realizara correctamente las actividades descritas en el programa fuente. Para el estudio de un compilador, es necesario dividir su trabajo en fases. Cada fase representa una transformación al código fuente para obtener el código objeto. La siguiente figura representa los componentes en que se divide un compilador. Las tres primeras fases realizan la tarea de análisis, y las demás la síntesis. En cada una de las fases se utiliza un administrador de la tabla de símbolos y un manejador de errores.
En la fase de análisis léxico se leen los caracteres del programa fuente y se agrupan en cadenas que representan los componentes léxicos. Cada componente léxico es una secuencia lógicamente coherente de caracteres relativa a un identificador, una palabra reservada, un operador o un carácter de puntuación. A la secuencia de caracteres que representa un componente léxico se le llama lexema (o con su nombre en inglés token). En el caso de los identificadores creados por el programador no solo se genera un componente léxico, sino que se genera otro lexema en la tabla de símbolos.
En esta fase, los componentes léxicos se agrupan en frases gramaticales que el compilador utiliza para sintetizar la salida. Análisis Semántico.
La fase de análisis semántico se intenta detectar instrucciones que tengan la estructura sintáctica correcta, pero que no tengan significado para la operación implicada.
Análisis Semántico: Este análisis es más difícil de formalizar, determina el tipo de los resultados intermedios, comprobar que los argumentos que tienen un operador pertenecen al conjunto de operadores posible, y si son compatibles entre sí.
Algunos compiladores generan una representación intermedia explícita del programa fuente, una vez que se han realizado las fases de análisis. Se puede considerar esta operación intermedia como un subprograma para una máquina abstracta. Esta representación intermedia debe tener dos propiedades importantes: debe ser fácil de producir y fácil de traducir al programa objeto.
En esta fase se trata de mejorar el código intermedio, de modo que resulte un código de máquina más rápido de ejecutar.
Esta constituye la fase final de un compilador. En ella se genera el código objeto que por lo general consiste en código en lenguaje máquina (código relocalizadle) o código en lenguaje ensamblador.
‘’‘Administrador de la tabla de símbolos. ‘’Una tabla de símbolos es una estructura de datos que contiene un registro por cada identificador. El registro incluye los campos para los atributos del identificador. El administrador de la tabla de símbolos se encarga de manejar los accesos a la tabla de símbolos, en cada una de las etapas de compilación de un programa.
En cada fase del proceso de compilación es posibles encontrar errores. Es conveniente que el tratamiento de los errores se haga de manera centralizada a través de un manejador de errores. De esta forma podrán controlarse más eficientemente los errores encontrados en cada una de las fases de la compilación de un programa.
BIBLIOGRAFIA
lunes, 14 de noviembre de 2011
AVANCES EN TRANSPLANTES DE LARINGE
AVANCES EN TRANSPLANTES DE LARINGE
Dan luz verde a los ensayos de trasplantes de laringe en el Reino Unido
El primer trasplante de laringe del Reino Unido podría realizarse en menos de un año, después de que el Royal College of Surgeons haya dado su aprobación para que se lleven a cabo los ensayos.
Un informe del organismo señaló que el procedimiento pionero podría ayudar a las personas con cáncer de laringe a volver a hablar y respirar con normalidad.
La decisión da apoyo a Martin Birchall, profesor de laringología en el Ear Institute del University College de Londres, principal científico involucrado en la pionera operación de 18 horas a una mujer en los EE.UU. en octubre pasado. Durante 11 años, Brenda Charett Jensen se había podido comunicar únicamente con un dispositivo electrónico de mano y respiraba a través de un tubo de traqueotomía. Dos semanas después de la operación, logró pronunciar sus primeras palabras y ahora puede hablar con normalidad.
Birchall tiene dos pacientes británicos esperando y afirma que ahora que tiene el respaldo de la universidad, puede solicitar financiación para empezar las complejas operaciones en el Reino Unido a principios del próximo año.
El respaldo del RCS no era previsible, dado que la cirugía no es para salvar vidas, sino para proporcionar al paciente una mejor la calidad de vida. Esto significa que hay que tener en cuenta los riesgos del procedimiento, de elevada complejidad, y del tratamiento de por vida utilizado para suprimir el sistema inmunológico.
La universidad parece tener menos dudas sobre el trasplante de laringe. El informe señala que hasta 1.000 pacientes al año, cuya laringe ha sido destruida en accidentes o por un cáncer, podrían beneficiarse de este procedimiento. No obstante, no valdría para algunos pacientes, como aquellos con cáncer recurrente o avanzado. El informe advierte de la necesidad de más investigación sobre la regeneración de los nervios e indica que hay que tener cuidado, involucrando a expertos en psicología, en la selección y el cuidado posterior de los pacientes.
sábado, 18 de junio de 2011
miércoles, 15 de junio de 2011
Aritmética del computador, Representación de los números Y Aritmética de punto flotante
Los computadores no almacenan los números con precisión infinita sino de forma aproximada empleando un número fijo de bits (apócope del término inglés Binary Digit) o bytes (grupos de ocho bits). Prácticamente todos los computadores permiten al programador elegir entre varias representaciones o 'tipos de datos'. Los diferentes tipos de datos pueden diferir en el número de bits empleados, pero también (lo que es más importante) en cómo el número representado es almacenado: en formato fijo (también denominado 'entero') o en punto flotante2 (denominado 'real').
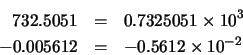
En general, un número real x distinto de cero, se representa en notación científica normalizada en la forma:
en donde r es un número tal que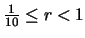 y n es un entero (positivo, negativo o cero). Exactamente del mismo modo podemos utilizar la notación científica en el sistema binario. En este caso, tenemos que:
y n es un entero (positivo, negativo o cero). Exactamente del mismo modo podemos utilizar la notación científica en el sistema binario. En este caso, tenemos que:
donde m es un entero. El número q se denomina mantisa y el entero m exponente. En un ordenador binario tanto q como m estarán representados como números en base 2. Puesto que la mantisa q está normalizada, en la representación binaria empleada se cumplirá que:
Se dice que un número real expresado como aparece en la ecuación (18) y que satisface la ecuación (19) tiene la forma de punto flotante normalizado. Si además puede representarse exactamente con |m| ocupando 7 bits y |q| ocupando 24 bits, entonces es un número de máquina en el MARC-323
La restricción de que |m| no requiera más de 7 bits significa que:
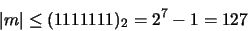
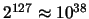 , la MARC-32 puede manejar números tan pequeños como 10-38 y tan grandes como 1038. Este no es un intervalo de valores suficientemente generoso, por lo que en muchos casos debemos recurrir a programas escritos en aritmética de doble precisión e incluso de precisión extendida.
, la MARC-32 puede manejar números tan pequeños como 10-38 y tan grandes como 1038. Este no es un intervalo de valores suficientemente generoso, por lo que en muchos casos debemos recurrir a programas escritos en aritmética de doble precisión e incluso de precisión extendida.
Como q debe representarse empleando no más de 24 bits significa que nuestros números de máquina tienen una precisión limitada cercana a las siete cifras decimales, ya que el bit menos significativo de la mantisa representa unidades de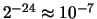 . Por tanto, los números expresados mediante más de siete dígitos decimales serán objeto de aproximación cuando se almacenen en el ordenador.
. Por tanto, los números expresados mediante más de siete dígitos decimales serán objeto de aproximación cuando se almacenen en el ordenador.
Por ejemplo: 0.5 representado en punto flotante en el MARC-32 (longitud de palabra de 32 bits) se almacena en la memoria del siguiente modo:
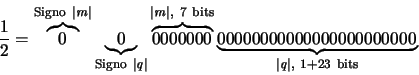
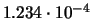 y 12542.29301 en base 2 empleando esta notación de punto fijo y notación de punto flotante MARC-32 con 32 bits. Calcule el error de almacenamiento cometido en cada caso.
y 12542.29301 en base 2 empleando esta notación de punto fijo y notación de punto flotante MARC-32 con 32 bits. Calcule el error de almacenamiento cometido en cada caso.
Solución: El número 26.32 en binario se escribe del siguiente modo:
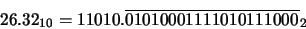
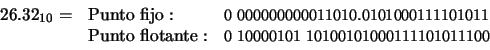
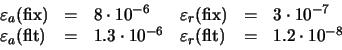
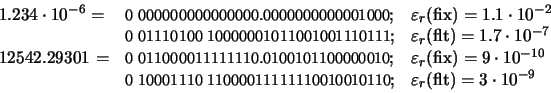
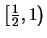 (exponente f = 0) es posible representar 224 números igualmente espaciados y separados por una distancia 1/224. De modo análogo, en cualquier intervalo
(exponente f = 0) es posible representar 224 números igualmente espaciados y separados por una distancia 1/224. De modo análogo, en cualquier intervalo 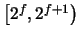 hay 224 números equiespaciados, pero su densidad en este caso es 2f/224. Por ejemplo, entre 220 = 1048576 y 221 = 2097152 hay 224 = 16777216 números, pero el espaciado entre dos números sucesivos es de sólo
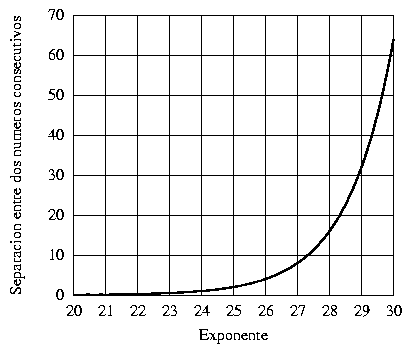
hay 224 números equiespaciados, pero su densidad en este caso es 2f/224. Por ejemplo, entre 220 = 1048576 y 221 = 2097152 hay 224 = 16777216 números, pero el espaciado entre dos números sucesivos es de sólo 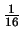 . De este hecho se deriva inmediatamente una regla práctica: cuando es necesario comparar dos números en punto flotante relativamente grandes, es siempre preferible comparar la diferencia relativa a la magnitud de los números. En la figura (1) se representa gráficamente la separación entre dos números consecutivos en función del exponente f en el rango f = [20,30].
. De este hecho se deriva inmediatamente una regla práctica: cuando es necesario comparar dos números en punto flotante relativamente grandes, es siempre preferible comparar la diferencia relativa a la magnitud de los números. En la figura (1) se representa gráficamente la separación entre dos números consecutivos en función del exponente f en el rango f = [20,30].
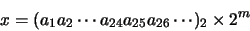
en donde cada ai es 0 ó 1 y el bit principal es a1 = 1. Un número de máquina se puede obtener de dos formas:
que se puede escribir de la siguiente forma:
Ejemplo 6: ¿Cómo se expresa en binario el número x = 2/3? ¿Cuáles son los números de máquina x' y x'' próximos en el MARC-32? El número 2/3 en binario se expresa como:
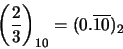
Los dos números de máquina próximos, cada uno con 24 bits, son:
en donde x' se ha obtenido por truncamiento y x'' mediante redondeo por exceso. Calculamos ahora las diferencias x - x' y x'' - x para estimar cual es el error cometido:
Por tanto, el número más próximo es fl(x) = x'' y los errores de redondeo absoluto y relativo son:
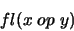
en donde op es +, -,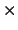 ó
ó 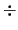 . Supondremos que en cada caso la mantisa del resultado es primero normalizada y después redondeada (operación que puede dar lugar a un desbordamiento que requeriría renormalizar el número). El valor de la mantisa redondeada a p bits, qr, se define como (de una forma más rigurosa que en el caso anterior):
. Supondremos que en cada caso la mantisa del resultado es primero normalizada y después redondeada (operación que puede dar lugar a un desbordamiento que requeriría renormalizar el número). El valor de la mantisa redondeada a p bits, qr, se define como (de una forma más rigurosa que en el caso anterior):
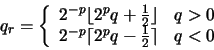
en donde la función redondeo por defecto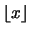 es el mayor entero menor o igual a x y la función redondeo por exceso
es el mayor entero menor o igual a x y la función redondeo por exceso 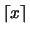 es el menor entero mayor o igual a x. Para números enteros, esta función se traduce en la bien conocida regla de sumar 1 en la posición p + 1. Teniendo en cuenta sólo la mantisa, redondear de este modo da lugar a un intervalo máximo del error de:
es el menor entero mayor o igual a x. Para números enteros, esta función se traduce en la bien conocida regla de sumar 1 en la posición p + 1. Teniendo en cuenta sólo la mantisa, redondear de este modo da lugar a un intervalo máximo del error de:
y un error relativo máximo en el intervalo:
Analizaremos ahora el error generado por cada una de las operaciones básicas:
Sin embargo, los errores de redondeo se acumulan a medida que aumenta el número de cálculos. Si en el proceso de calcular un valor se llevan a cabo N operaciones aritméticas es posible obtener, en el mejor de los casos, un error de redondeo total del orden de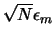 4 (que coincide con el caso en que los errores de redondeo están aleatoriamente distribuidos, por lo que se produce una cancelación parcial). Desafortunadamente, este error puede crecer muy rápidamente por dos motivos:
4 (que coincide con el caso en que los errores de redondeo están aleatoriamente distribuidos, por lo que se produce una cancelación parcial). Desafortunadamente, este error puede crecer muy rápidamente por dos motivos:
que son:
Cualquiera de estas dos expresiones da problemas cuando a, c o ambos, son pequeños. En estos casos, el valor del discriminante es muy próximo al valor de b:
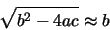
por lo que la diferencia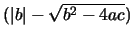 viene afectada de un error de redondeo importante. En efecto, la ecuación (23) evalúa bien la raíz más grande en valor absoluto, pero da pésimos resultados al estimar la raíz menor en valor absoluto. Por otra parte, la ecuación (24) calcula bien la raíz menor (siempre en valor absoluto) pero no la raíz más grande. La solución del problema pasa por emplear una expresión mejor condicionada. En este caso, es preferible calcular previamente:
viene afectada de un error de redondeo importante. En efecto, la ecuación (23) evalúa bien la raíz más grande en valor absoluto, pero da pésimos resultados al estimar la raíz menor en valor absoluto. Por otra parte, la ecuación (24) calcula bien la raíz menor (siempre en valor absoluto) pero no la raíz más grande. La solución del problema pasa por emplear una expresión mejor condicionada. En este caso, es preferible calcular previamente:
y las dos raíces a partir de valor de q como:
Ejemplo: Calcular las raíces de la siguiente ecuación cuadrática:
siendo:
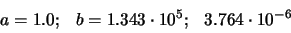
Solución: Empleando la ecuación (23), obtenemos:
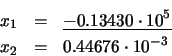
Sin embargo, empleando la expresión (24):
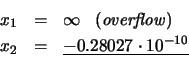
Por último, empleando las expresiones (25) y (26) se obtienen ambas soluciones correctas:
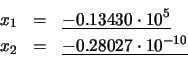
en donde F es el mayor exponente positivo representable (generalmente 27 - 1) y M es la mantisa que tiene todos sus bits puestos a 1 ( M = 1 - 224). Un desbordamiento por exceso de punto flotante (overflow en inglés) se origina cuando el resultado de una operación de punto flotante tiene una magnitud mayor que la representada por la ecuación (27). Ejemplo: Con q = 8 (y por tanto F = 27 - 1 = 127), las siguientes operaciones aritméticas dan lugar a desbordamiento por exceso:
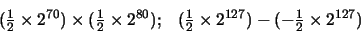
El desbordamiento por defecto (underflow en inglés) se produce cuando el resultado de una operación en punto flotante es demasiado pequeño, aunque no nulo, como para que se pueda expresar en la forma dada por la ecuación (18). El número más pequeño representable suponiendo que siempre trabajamos con mantisas normalizadas es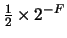 , en donde -F es el exponente negativo más grande permitido (generalmente -2-q-1). Por ejemplo, con q=8 resulta -F = -128.
, en donde -F es el exponente negativo más grande permitido (generalmente -2-q-1). Por ejemplo, con q=8 resulta -F = -128.
Ejemplo: Con q = 8 (y por tanto -F = -128), la siguiente operación aritmética da lugar a desbordamiento por defecto:
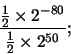
El desbordamiento por exceso es casi siempre resultado de un error en el cálculo. Sin embargo, en el caso del desobordamiento por defecto, en muchas ocasiones es posible continuar el cálculo reemplazando el resultado por cero.
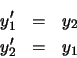
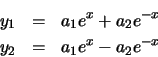
y1(0) = -y2(0) = 1 es posible determinar que el valor de las constantes a1 y a2 es: a1 = 0 & y & a2 = 1
Hasta este punto, las soluciones son exactas. Sin embargo, supongamos que el sistema de ecuaciones anterior se resuelve empleando un método numérico cualquiera con el fin de calcular los valores de las funciones y1 y y2 en una secuencia de puntos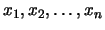 y que el error del método da lugar a un valor de
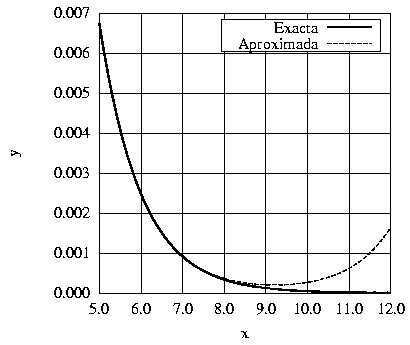
y que el error del método da lugar a un valor de 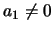 . Ya que a1 multiplica a un exponencial creciente cualquier valor, por pequeño que sea, de a1 dará lugar a que el término ex domine sobre el término e-x para valores suficientemente grandes de x (ver figura (2)). La conclusión que se obtiene es que no es posible calcular una solución al sistema de ecuaciones diferenciales anterior que, para valores suficientemente grandes de x, no de lugar a un error arbitrariamente grande en relación con la solución exacta.
. Ya que a1 multiplica a un exponencial creciente cualquier valor, por pequeño que sea, de a1 dará lugar a que el término ex domine sobre el término e-x para valores suficientemente grandes de x (ver figura (2)). La conclusión que se obtiene es que no es posible calcular una solución al sistema de ecuaciones diferenciales anterior que, para valores suficientemente grandes de x, no de lugar a un error arbitrariamente grande en relación con la solución exacta.
 , su representación en una dada base
, su representación en una dada base  consiste en escribirlo como
consiste en escribirlo como
En representación binaria un número entero  se escribe como
se escribe como

 ,
,  , etc) o periódicos (
, etc) o periódicos ( ,
,  , ...) en el sistema decimal. La forma convencional de almacenar números reales en la memoria de una computadora es mediante el método llamado de punto flotante o floating point. Uno de los sistemas más comunes es la representación de números reales en simple precisión utilizada en la convención IEEE. En dicho sistema cada número de precisión simple ocupa 4 bytes (32 bits) que se destinan a: el signo (1 bit), un exponente (8 bits) y la parte fraccionaria de la mantisa (23 bits)1. De esta manera un número está determinado por estas tres cantidades
, ...) en el sistema decimal. La forma convencional de almacenar números reales en la memoria de una computadora es mediante el método llamado de punto flotante o floating point. Uno de los sistemas más comunes es la representación de números reales en simple precisión utilizada en la convención IEEE. En dicho sistema cada número de precisión simple ocupa 4 bytes (32 bits) que se destinan a: el signo (1 bit), un exponente (8 bits) y la parte fraccionaria de la mantisa (23 bits)1. De esta manera un número está determinado por estas tres cantidades
En esta representación, los 8 bits utilizados permiten que el exponente se encuentre en el rango  . Se utiliza la constante
. Se utiliza la constante  para también obtener resultados negativos2. Observe que para ganar un bit, se omite la parte entera de la mantisa que se supone igual a 1. Esta representación se llama normalizada y se utiliza para todos los números, excepto aquellos muy grandes o muy pequeños. En particular, esta convención no permite representar el número 0.
para también obtener resultados negativos2. Observe que para ganar un bit, se omite la parte entera de la mantisa que se supone igual a 1. Esta representación se llama normalizada y se utiliza para todos los números, excepto aquellos muy grandes o muy pequeños. En particular, esta convención no permite representar el número 0.
Para aclarar los conceptos, consideremos algunos ejemplos de números normalizados en precisión simple:
Hemos representado entre paréntesis la parte entera de la mantisa (que es igual a 1 siempre por convención. Debe notarse que el número final se obtiene considerando que:
 a sistema binario. El bit de signo es 0. El número puede expresarse como la fracción
a sistema binario. El bit de signo es 0. El número puede expresarse como la fracción  y es mayor que 2 por lo que debemos sacar un exponente positivo; en este caso, factorizamos por
y es mayor que 2 por lo que debemos sacar un exponente positivo; en este caso, factorizamos por  y nos quda
y nos quda  que puede escribirse como
que puede escribirse como


Una de las consecuencias más importantes de usar una representación de punto flotante (con signo, mantisa y exponente) es que dos números deben tener el mismo exponente para poder ser sumados o restados. Consideremos por ejemplo la suma de los dos números anteriores  y
y  en sistema binario
en sistema binario
Aquí hemos cambiado a una forma no normalizada para utilizar el mismo exponente en ambos números. Este procedimiento disminuye la cantidad de dígitos significantes.
Ejercicios
...tiene el valor 1/10 + 2/100 + 5/1000, y de la misma manera la fracción binaria
...tiene el valor 0/2 + 0/4 + 1/8. Estas dos fracciones tienen valores idénticos, la única diferencia real es que la primera está escrita en notación fraccional en base 10 y la segunda en base 2.
Desafortunadamente, la mayoría de las fracciones decimales no pueden representarse exactamente como fracciones binarias. Como consecuencia, en general los números de punto flotante decimal que ingresás en la computadora son sólo aproximados por los números de punto flotante binario que realmente se guardan en la máquina.
El problema es más fácil de entender primero en base 10. Considerá la fracción 1/3. Podés aproximarla como una fracción de base 10
...o, mejor,
...o, mejor,
...y así. No importa cuantos dígitos desees escribir, el resultado nunca será exactamente 1/3, pero será una aproximación cada vez mejor de 1/3.
De la misma manera, no importa cuantos dígitos en base 2 quieras usar, el valor decimal 0.1 no puede representarse exactamente como una fracción en base 2. En base 2, 1/10 es la siguiente fracción que se repite infinitamente:
Frená en cualquier número finito de bits, y tendrás una aproximación. Es por esto que ves cosas como:
En la mayoría de las máquinas de hoy en día, eso es lo que verás si ingresás 0.1 en un prompt de Python. Quizás no, sin embargo, porque la cantidad de bits usados por el hardware para almacenar valores de punto flotante puede variar en las distintas máquinas, y Python sólo muestra una aproximación del valor decimal verdadero de la aproximación binaria guardada por la máquina. En la mayoría de las máquinas, si Python fuera a mostrar el verdadero valor decimal de la aproximación almacenada por 0.1, tendría que mostrar sin embargo
El prompt de Python usa la función integrada repr() para obtener una versión en cadena de caracteres de todo lo que muestra. Para flotantes, repr(float) redondea el valor decimal verdadero a 17 dígitos significativos, dando
repr(float) produce 17 dígitos significativos porque esto es suficiente (en la mayoría de las máquinas) para que se cumpla eval(repr(x)) == x exactamente para todos los flotantes finitos X, pero redondeando a 16 dígitos no es suficiente para que sea verdadero.
Notá que esta es la verdadera naturaleza del punto flotante binario: no es un error de Python, y tampoco es un error en tu código. Verás lo mismo en todos los lenguajes que soportan la aritmética de punto flotante de tu hardware (a pesar de que en algunos lenguajes por omisión no muestren la diferencia, o no lo hagan en todos los modos de salida).
La función integrada :func: str de Python produce sólo 12 dígitos significativos, y quizás quieras usar esa. Normalmente eval(str(x)) no reproducirá x, pero la salida quizás sea más placentera de ver:
Es importante darse cuenta de que esto es, realmente, una ilusión: el valor en la máquina no es exactamente 1/10, simplemente estás redondeando el valor que se muestra del valor verdadero de la máquina.
A esta se siguen otras sorpresas. Por ejemplo, luego de ver:
...quizás estés tentado de usar la función round() para recortar el resultado al dígito que esperabas. Pero es lo mismo:
El problema es que el valor de punto flotante binario almacenado para “0.1” ya era la mejor aproximación binaria posible de 1/10, de manera que intentar redondearla nuevamente no puede mejorarla: ya era la mejor posible.
Otra consecuencia es que como 0.1 no es exactamente 1/10, sumar diez valores de 0.1 quizás tampoco dé exactamente 1.0:
La aritmética de punto flotante binaria tiene varias sorpresas como esta. El problema con “0.1” es explicado con detalle abajo, en la sección “Error de Representación”. Mirá los Peligros del Punto Flotante (en inglés, The Perils of Floating Point) para una más completa recopilación de otras sorpresas normales.
Como dice cerca del final, “no hay respuestas fáciles”. A pesar de eso, ¡no le tengas mucho miedo al punto flotante! Los errores en las operaciones flotantes de Python se heredan del hardware de punto flotante, y en la mayoría de las máquinas están en el orden de no más de una 1 parte en 2**53 por operación. Eso es más que adecuado para la mayoría de las tareas, pero necesitás tener en cuenta que no es aritmética decimal, y que cada operación de punto flotante sufre un nuevo error de redondeo.
A pesar de que existen casos patológicos, para la mayoría de usos casuales de la aritmética de punto flotante al final verás el resultado que esperás si simplemente redondeás lo que mostrás de tus resultados finales al número de dígitos decimales que esperás. str() es normalmente suficiente, y para un control más fino mirá los parámetros del método de formateo str.format() en formatstrings.
Error de representación se refiere al hecho de que algunas (la mayoría) de las fracciones decimales no pueden representarse exactamente como fracciones binarias (en base 2). Esta es la razón principal de por qué Python (o Perl, C, C++, Java, Fortran, y tantos otros) frecuentemente no mostrarán el número decimal exacto que esperás:
¿Por qué es eso? 1/10 no es representable exactamente como una fracción binaria. Casi todas las máquinas de hoy en día (Noviembre del 2000) usan aritmética de punto flotante IEEE-754, y casi todas las plataformas mapean los flotantes de Python al “doble precisión” de IEEE-754. Estos “dobles” tienen 53 bits de precisión, por lo tanto en la entrada la computadora intenta convertir 0.1 a la fracción más cercana que puede de la forma J/2***N* donde J es un entero que contiene exactamente 53 bits. Reescribiendo
...como
...y recordando que J tiene exactamente 53 bits (es >= 2**52 pero < 2**53), el mejor valor para N es 56:
O sea, 56 es el único valor para N que deja J con exactamente 53 bits. El mejor valor posible para J es entonces el cociente redondeado:
Ya que el resto es más que la mitad de 10, la mejor aproximación se obtiene redondeándolo:
Por lo tanto la mejor aproximación a 1/10 en doble precisión 754 es eso sobre 2**56, o
Notá que como lo redondeamos, esto es un poquito más grande que 1/10; si no lo hubiéramos redondeado, el cociente hubiese sido un poquito menor que 1/10. ¡Pero no hay caso en que sea exactamente 1/10!
Entonces la computadora nunca “ve” 1/10: lo que ve es la fracción exacta de arriba, la mejor aproximación al flotante doble de 754 que puede obtener:
Si multiplicamos esa fracción por 10**30, podemos ver el valor (truncado) de sus 30 dígitos más significativos:
...lo que significa que el valor exacto almacenado en la computadora es aproximadamente igual al valor decimal 0.100000000000000005551115123125. Redondeando eso a 17 dígitos significativos da el 0.10000000000000001 que Python muestra (bueno, mostraría en cualquier plataforma que cumpla con 754 cuya biblioteca en C haga la mejor conversión posible en entrada y salida... ¡la tuya quizás no!).
3.1 Aritmética de punto fijo
Un entero se puede representar empleando todos los bits de una palabra de computadora, con la salvedad de que se debe reservar un bit para el signo. Por ejemplo, en una máquina con longitud de palabra de 32 bits, los enteros están comprendidos entre -(231 - 1) y 231 - 1 = 2147483647. Un número representado en formato entero es 'exacto'. Las operaciones aritméticas entre números enteros son también 'exactas' siempre y cuando:- 1.
- La solución no esté fuera del rango del número entero más grande o más pequeño que se puede representar (generalmente con signo). En estos casos se dice que se comete un error de desbordamiento por exceso o por defecto (en inglés: Overflow y Underflow) y es necesario recurrir a técnicas de escalado para llevar a cabo las operaciones.
- 2.
- La división se interpreta que da lugar a un número entero, despreciando cualquier resto.
3.2 Números en punto flotante
3.2.1 Notación científica normalizada
En el sistema decimal, cualquier número real puede expresarse mediante la denominada notación científica normalizada. Para expresar un número en notación científica normalizada multiplicamos o dividimos por 10 tantas veces como sea necesario para que todos los dígitos aparezcan a la derecha del punto decimal y de modo que el primer dígito después del punto no sea cero. Por ejemplo: En general, un número real x distinto de cero, se representa en notación científica normalizada en la forma:
en donde r es un número tal que
donde m es un entero. El número q se denomina mantisa y el entero m exponente. En un ordenador binario tanto q como m estarán representados como números en base 2. Puesto que la mantisa q está normalizada, en la representación binaria empleada se cumplirá que:
3.2.2 Representación de los números en punto flotante
En un ordenador típico los números en punto flotante se representan de la manera descrita en el apartado anterior, pero con ciertas restricciones sobre el número de dígitos de q y m impuestas por la longitud de palabra disponible (es decir, el número de bits que se van a emplear para almacenar un número). Para ilustrar este punto, consideraremos un ordenador hipotético que denominaremos MARC-32 y que dispone de una longitud de palabra de 32 bits (muy similar a la de muchos ordenadores actuales). Para representar un número en punto flotante en el MARC-32, los bits se acomodan del siguiente modo:| Signo del número real x: | 1 bit |
| Signo del exponente m: | 1 bit |
| Exponente (entero |m|): | 7 bits |
| Mantisa (número real |q|): | 23 bits |
Se dice que un número real expresado como aparece en la ecuación (18) y que satisface la ecuación (19) tiene la forma de punto flotante normalizado. Si además puede representarse exactamente con |m| ocupando 7 bits y |q| ocupando 24 bits, entonces es un número de máquina en el MARC-323
La restricción de que |m| no requiera más de 7 bits significa que:
Como q debe representarse empleando no más de 24 bits significa que nuestros números de máquina tienen una precisión limitada cercana a las siete cifras decimales, ya que el bit menos significativo de la mantisa representa unidades de
Por ejemplo: 0.5 representado en punto flotante en el MARC-32 (longitud de palabra de 32 bits) se almacena en la memoria del siguiente modo:
Solución: El número 26.32 en binario se escribe del siguiente modo:
3.3 Aritmética de punto flotante
En este apartado analizaremos los errores inherentes a la aritmética de los números de punto flotante. Primero consideraremos el error que surge como consecuencia de que los números reales no se pueden almacenar, en general, de forma exacta en un ordenador. Después analizaremos las cuatro operaciones aritméticas básicas y finalmente ampliaremos el estudio a un cálculo más complejo.3.3.1 Números de máquina aproximados
Estamos interesados en estimar el error en que se incurre al aproximar un número real positivo x mediante un número de máquina del MARC-32. Si representamos el número mediante:en donde cada ai es 0 ó 1 y el bit principal es a1 = 1. Un número de máquina se puede obtener de dos formas:
- Truncamiento: descartando todos los bits excedentes
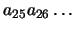 . El número resultante, x' es siempre menor que x (se encuentra a la izquierda de x en la recta real).
. El número resultante, x' es siempre menor que x (se encuentra a la izquierda de x en la recta real). - Redondeo por exceso: Aumentamos en una unidad el último bit remanente a24 y después eliminamos el exceso de bits como en el caso anterior.
que se puede escribir de la siguiente forma:
Ejemplo 6: ¿Cómo se expresa en binario el número x = 2/3? ¿Cuáles son los números de máquina x' y x'' próximos en el MARC-32? El número 2/3 en binario se expresa como:
Los dos números de máquina próximos, cada uno con 24 bits, son:
| x' | = | ||
| x'' | = |
en donde x' se ha obtenido por truncamiento y x'' mediante redondeo por exceso. Calculamos ahora las diferencias x - x' y x'' - x para estimar cual es el error cometido:
| x - x' | = | 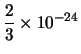 | |
| x'' - x | = | 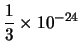 |
Por tanto, el número más próximo es fl(x) = x'' y los errores de redondeo absoluto y relativo son:
| |fl(x) - x| | = | | |
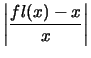 | = | 2-25 < 2-24 |
3.3.2 Las operaciones básicas
Vamos a analizar el resultado de operar sobre dos números en punto flotante normalizado de l-dígitos de longitud, x e y, que producen un resultado normalizado de l-dígitos. Expresaremos esta operación como:en donde op es +, -,
en donde la función redondeo por defecto
y un error relativo máximo en el intervalo:
Analizaremos ahora el error generado por cada una de las operaciones básicas:
- Multiplicación.
- La operación de multiplicar dos números expresados en punto flotante implica sumar los exponentes y multiplicar las mantisas. Si la mantisa resultante no está normalizada, se recurre a renormalizar el resultado ajustando adecuadamente el exponente. Después, es necesario redondear la mantisa a p bits. Para analizar el error de esta operación supongamos dos números:
Tenemos entonces que el producto será:
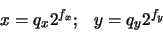 xy = qx qy 2fx + fyen donde el valor de la mantisa se encontrará en el rango:ya que tanto x como y satisfacen la ecuación (19). Por tanto, la normalización del producto qx qy implica un desplazamiento a la derecha de, como máximo, una posición. La mantisa redondeada será entonces uno de estos dos posibles valores:
xy = qx qy 2fx + fyen donde el valor de la mantisa se encontrará en el rango:ya que tanto x como y satisfacen la ecuación (19). Por tanto, la normalización del producto qx qy implica un desplazamiento a la derecha de, como máximo, una posición. La mantisa redondeada será entonces uno de estos dos posibles valores: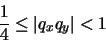 en donde
en donde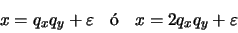
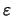 , que es el error de redondeo, cumple la ecuación (21). Tenemos entonces:
en donde, de acuerdo con la ecuación (22), tenemos:
, que es el error de redondeo, cumple la ecuación (21). Tenemos entonces:
en donde, de acuerdo con la ecuación (22), tenemos: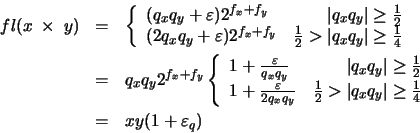 Por tanto, la cota del error relativo en la multiplicación es la misma que la que surge por redondear la mantisa.
Por tanto, la cota del error relativo en la multiplicación es la misma que la que surge por redondear la mantisa.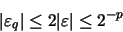
- División.
- Para llevar a cabo la división en punto flotante, se divide la mitad de la mantisa del numerador por la mantisa del denominador (para evitar cocientes mayores de la unidad), mientras que los exponentes se restan. Esto es:
Puesto que ambas mantisas satisfacen la ecuación (18), el valor del cociente estará acotado entre los límites:
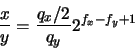 Aplicando un análisis similar al empleado en el caso de la multiplicación, obtenemos:
Aplicando un análisis similar al empleado en el caso de la multiplicación, obtenemos: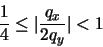 en donde, de acuerdo con la ecuación (22), tenemos:
en donde, de acuerdo con la ecuación (22), tenemos: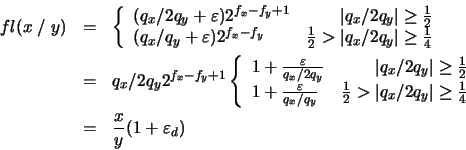 Es decir, la cota máxima del error relativo en la división, como en el caso anterior, es la misma que la que surge por redondear la mantisa.
Es decir, la cota máxima del error relativo en la división, como en el caso anterior, es la misma que la que surge por redondear la mantisa.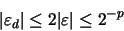
- Adición y sustracción.
- La operación de suma o resta se realiza del siguiente modo: se toma la mantisa del operando de menor magnitud (supongamos que es y) y se desplaza fx - fy posiciones a la derecha. La mantisa resultante es sumada (o restada) y el resultado se normaliza y después se redondea. Es decir:
El análisis del error cometido en esta operación es más complejo que los estudiados hasta ahora, por lo que no lo vamos a ver en detalle. Sin embargo, el resultado final indica que la cota máxima del error cometido en la adición y la sustracción viene dado por:
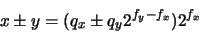
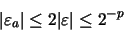
Sin embargo, los errores de redondeo se acumulan a medida que aumenta el número de cálculos. Si en el proceso de calcular un valor se llevan a cabo N operaciones aritméticas es posible obtener, en el mejor de los casos, un error de redondeo total del orden de
- Es muy frecuente que la regularidad del cálculo o las peculiaridades del computador den lugar a que el error se acumule preferentemente en una dirección; en cuyo caso el error de redondeo se puede aproximar a
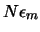 .
. - En circunstancias especialmente desfavorables pueden existir operaciones que incremente espectacularmente el error de redondeo. Generalmente, este fenómeno se da cuando se calcula la diferencia entre dos números muy próximos, dando lugar a un resultado en el cual los únicos bits significativos que no se cancelan son los de menor orden (en los únicos en que difieren). Puede parecer que la probabilidad de que se de dicha situación es pequeña, sin embargo, algunas expresiones matemáticas fomentan este fenómeno.
ax2 + bx + c = 0
que son:
Cualquiera de estas dos expresiones da problemas cuando a, c o ambos, son pequeños. En estos casos, el valor del discriminante es muy próximo al valor de b:
por lo que la diferencia
y las dos raíces a partir de valor de q como:
Ejemplo: Calcular las raíces de la siguiente ecuación cuadrática:
ax2 + bx + c = 0
siendo:
Solución: Empleando la ecuación (23), obtenemos:
Sin embargo, empleando la expresión (24):
Por último, empleando las expresiones (25) y (26) se obtienen ambas soluciones correctas:
3.4 Desbordamiento por exceso y desbordamiento por defecto
En la discusión anterior, hemos ignorado la posibilidad de que el resultado de una operación del punto flotante pueda no ser representable mediante el esquema fijo (l-bits) empleado por el ordenador. La magnitud más grande que puede representarse mediante la fórmula general (18) es:en donde F es el mayor exponente positivo representable (generalmente 27 - 1) y M es la mantisa que tiene todos sus bits puestos a 1 ( M = 1 - 224). Un desbordamiento por exceso de punto flotante (overflow en inglés) se origina cuando el resultado de una operación de punto flotante tiene una magnitud mayor que la representada por la ecuación (27). Ejemplo: Con q = 8 (y por tanto F = 27 - 1 = 127), las siguientes operaciones aritméticas dan lugar a desbordamiento por exceso:
El desbordamiento por defecto (underflow en inglés) se produce cuando el resultado de una operación en punto flotante es demasiado pequeño, aunque no nulo, como para que se pueda expresar en la forma dada por la ecuación (18). El número más pequeño representable suponiendo que siempre trabajamos con mantisas normalizadas es
Ejemplo: Con q = 8 (y por tanto -F = -128), la siguiente operación aritmética da lugar a desbordamiento por defecto:
El desbordamiento por exceso es casi siempre resultado de un error en el cálculo. Sin embargo, en el caso del desobordamiento por defecto, en muchas ocasiones es posible continuar el cálculo reemplazando el resultado por cero.
3.5 Condicionamiento y estabilidad
La 'inestabilidad' en un cálculo es un fenómeno que se produce cuando los errores de redondeo individuales se propagan a través del cálculo incrementalmente. Veamos brevemente este fenómeno y el problema relacionado con este: el 'condicionamiento' del método o del problema. La mejor forma de ver este fenómeno es a través de un ejemplo. Supongamos el siguiente sistema de ecuaciones diferenciales:Hasta este punto, las soluciones son exactas. Sin embargo, supongamos que el sistema de ecuaciones anterior se resuelve empleando un método numérico cualquiera con el fin de calcular los valores de las funciones y1 y y2 en una secuencia de puntos
Representación de Números
Representación Numérica en una base
Dado un número
donde el signo  es igual a 0 o 1 y los coeficientes
es igual a 0 o 1 y los coeficientes  son enteros positivos menores que . En la vida real la suma tiene sólo un número finito de términos por lo que algunos números son sólo representados en forma aproximada. Usualmente, utilizamos el sistema decimal de numeración (
son enteros positivos menores que . En la vida real la suma tiene sólo un número finito de términos por lo que algunos números son sólo representados en forma aproximada. Usualmente, utilizamos el sistema decimal de numeración ( ) pero la representación numérica en sistemas digitales se realiza en general en base 2, denominado sistema de numeración binaria, y ocasionalmente en base 16 (sistema hexadecimal). Los números se representan en memoria como una cadena de bits que pueden tomar los valores 0 ó 1. Se denomina byte a un grupo de 8 bits consecutivos.
) pero la representación numérica en sistemas digitales se realiza en general en base 2, denominado sistema de numeración binaria, y ocasionalmente en base 16 (sistema hexadecimal). Los números se representan en memoria como una cadena de bits que pueden tomar los valores 0 ó 1. Se denomina byte a un grupo de 8 bits consecutivos.
Representación de números enteros
En representación binaria un número entero donde cada coeficiente es igual a 1 o 0. Usualmente los números enteros ocupaban 4 bytes de memoria (32 bits), aunque en las computadoras modernas se pueden utilizar enteros de 64 bits. Los números que pueden almacenarse en la representación de 4 bytes están en el rango:
para números enteros sin signo. Si se utiliza el primer bit de la izquierda como signo (0, positivo; 1, negativo) el rango se reduce a  y
y  para enteros con signo.
para enteros con signo.
Representación de números reales
Las computadoras, con un número finito de bits, no pueden almacenar todos los números reales en forma exacta. Esto es similar a lo que ocurre con los números irracionales (como
Algunos ejemplos
Para aclarar los conceptos, consideremos algunos ejemplos de números normalizados en precisión simple: - El signo es positivo (bit de signo igual a 0).
- El exponente se obtiene como
 , que en sistema decimal da
, que en sistema decimal da  .
. - La mantisa
 se obtiene sumando: 1 (implícito), 1/8, 1/16, 1/32, 1/64 y 1/1024.
se obtiene sumando: 1 (implícito), 1/8, 1/16, 1/32, 1/64 y 1/1024.
por lo que, después de eliminar la parte entera y agregando el signo y el exponente, el número es:
Aritmética con números binarios
Una de las consecuencias más importantes de usar una representación de punto flotante (con signo, mantisa y exponente) es que dos números deben tener el mismo exponente para poder ser sumados o restados. Consideremos por ejemplo la suma de los dos números anteriores
Casos particulares y otros ejemplos
- ¿Qué pasa cuándo el número es exactamente cero?.
La convención dice que se interpreta exactamente cero cuando todos los bits son 0. Esto significa, No sólo los de la mantisa sino también los del exponente. Nótese que para números de 64 bits (8 bytes) se interpreta que el número  , ya que el exponente ha sido corrido en 127.
, ya que el exponente ha sido corrido en 127.
- Representación de infinitos varios
Hay dos tipos de infinitos: positivos y negativos. La convención para representar estos números dice que un número se considera infinito si cada uno de los bits del exponente es 1 y los de la mantisa son 0. El signo permite distinguir entre  y
y  .
.
- Otro caso particular en la convención es cuando necesitamos representar algo que no corresponde a un número bien definido (
 , por ejemplo). El resultado de estas operaciones no son números (uno obtiene algo como
, por ejemplo). El resultado de estas operaciones no son números (uno obtiene algo como  NaN) y la representación interna corresponde a todos los bits del exponente en 1 y además al menos uno de la mantisa es 1 también.
NaN) y la representación interna corresponde a todos los bits del exponente en 1 y además al menos uno de la mantisa es 1 también.
Ejercicios
|
ARITMERTICA DE PUNTO FLKOTANTE
Problemas y Limitaciones
Los números de punto flotante se representan en el hardware de la computadora en fracciones en base 2 (binario). Por ejemplo, la fracción decimal0.1250.001Desafortunadamente, la mayoría de las fracciones decimales no pueden representarse exactamente como fracciones binarias. Como consecuencia, en general los números de punto flotante decimal que ingresás en la computadora son sólo aproximados por los números de punto flotante binario que realmente se guardan en la máquina.
El problema es más fácil de entender primero en base 10. Considerá la fracción 1/3. Podés aproximarla como una fracción de base 10
0.30.330.333De la misma manera, no importa cuantos dígitos en base 2 quieras usar, el valor decimal 0.1 no puede representarse exactamente como una fracción en base 2. En base 2, 1/10 es la siguiente fracción que se repite infinitamente:
0.0001100110011001100110011001100110011001100110011...>>> 0.1
0.10000000000000001>>> 0.1
0.10000000000000000555111512312578270211815834045410156250.10000000000000001Notá que esta es la verdadera naturaleza del punto flotante binario: no es un error de Python, y tampoco es un error en tu código. Verás lo mismo en todos los lenguajes que soportan la aritmética de punto flotante de tu hardware (a pesar de que en algunos lenguajes por omisión no muestren la diferencia, o no lo hagan en todos los modos de salida).
La función integrada :func: str de Python produce sólo 12 dígitos significativos, y quizás quieras usar esa. Normalmente eval(str(x)) no reproducirá x, pero la salida quizás sea más placentera de ver:
>>> print str(0.1)
0.1A esta se siguen otras sorpresas. Por ejemplo, luego de ver:
>>> 0.1
0.10000000000000001>>> round(0.1, 1)
0.10000000000000001Otra consecuencia es que como 0.1 no es exactamente 1/10, sumar diez valores de 0.1 quizás tampoco dé exactamente 1.0:
>>> suma = 0.0
>>> for i in range(10):
... suma += 0.1
...
>>> suma
0.9999999999999999Como dice cerca del final, “no hay respuestas fáciles”. A pesar de eso, ¡no le tengas mucho miedo al punto flotante! Los errores en las operaciones flotantes de Python se heredan del hardware de punto flotante, y en la mayoría de las máquinas están en el orden de no más de una 1 parte en 2**53 por operación. Eso es más que adecuado para la mayoría de las tareas, pero necesitás tener en cuenta que no es aritmética decimal, y que cada operación de punto flotante sufre un nuevo error de redondeo.
A pesar de que existen casos patológicos, para la mayoría de usos casuales de la aritmética de punto flotante al final verás el resultado que esperás si simplemente redondeás lo que mostrás de tus resultados finales al número de dígitos decimales que esperás. str() es normalmente suficiente, y para un control más fino mirá los parámetros del método de formateo str.format() en formatstrings.
14.1. Error de Representación¶
Esta sección explica el ejemplo “0.1” en detalle, y muestra como en la mayoría de los casos vos mismo podés realizar un análisis exacto como este. Se asume un conocimiento básico de la representación de punto flotante binario.Error de representación se refiere al hecho de que algunas (la mayoría) de las fracciones decimales no pueden representarse exactamente como fracciones binarias (en base 2). Esta es la razón principal de por qué Python (o Perl, C, C++, Java, Fortran, y tantos otros) frecuentemente no mostrarán el número decimal exacto que esperás:
>>> 0.1
0.100000000000000011 / 10 ~= J / (2**N)J ~= 2**N / 10>>> 2**52
4503599627370496L
>>> 2**53
9007199254740992L
>>> 2**56/10
7205759403792793L>>> q, r = divmod(2**56, 10)
>>> r
6L>>> q+1
7205759403792794L7205759403792794 / 72057594037927936Entonces la computadora nunca “ve” 1/10: lo que ve es la fracción exacta de arriba, la mejor aproximación al flotante doble de 754 que puede obtener:
>>> .1 * 2**56
7205759403792794.0>>> 7205759403792794 * 10**30 / 2**56
100000000000000005551115123125L
Suscribirse a:
Entradas (Atom)